Evaluate models with Weave
What is Weave?
W&B Weave helps developers who are building and iterating on their AI apps to create apples-to-apples evaluations that score the behavior of any aspect of their app, and examine and debug failures by easily inspecting inputs and outputs.
Get started with Weave
First, create a W&B account at https://wandb.ai and copy your API key from https://wandb.ai/authorize.
Then, you can follow along in the below Colab notebook that demonstrates Weave evaluating an LLM (in this case, OpenAI, for which you will also need an API key).
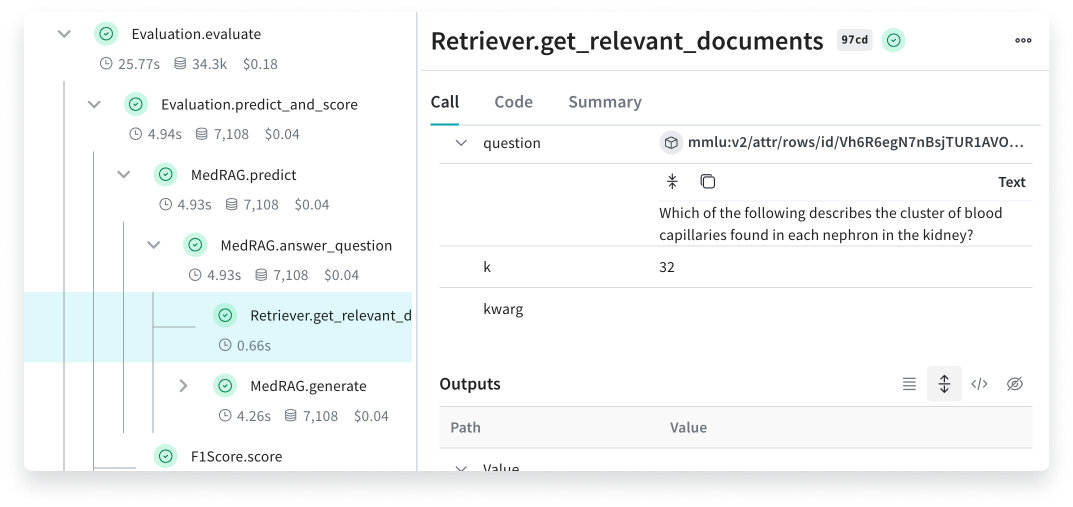
After running through the steps, browse your dashboard in Weave to see the tracing data Weave logs when executing your LLM app code, and see breakdowns of execution time, API cost, etc. Try the dashboard links Weave generates after every call in the Colab notebook and see how Weave breaks down errors and stack traces, tracks costs, and assists you in reverse-engineering the behavior of the LLM.
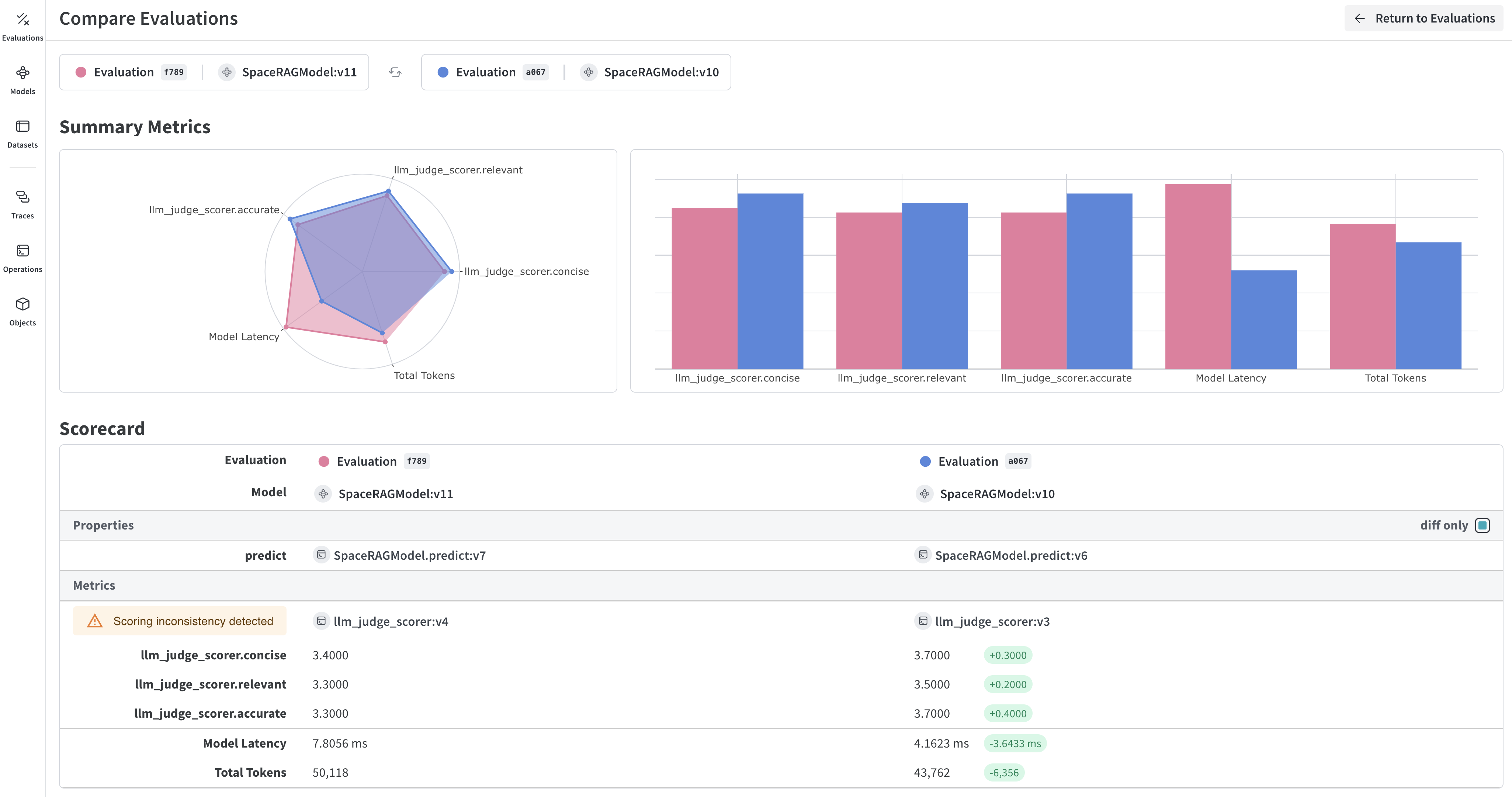
Use Weave to evaluate models in production
This tutorial on how to build an evaluation pipeline with Weave demonstrates how multiple versions of an application that uses a model is evolving using the weave.Evaluation function, which assess a Model's performance on a set of examples using a list of specified scoring functions or weave.scorer.Scorer classes, producing dashboards with advanced breakdowns of the model's performance.